小型Hadoop集群的数据分层调度处理算法分析
随着大数据技术的快速发展,小型Hadoop集群在企业数据处理及存储服务中的应用日益广泛。数据分层调度处理算法作为Hadoop集群中的核心组成部分,对提高数据处理效率、优化资源分配具有重要意义。本文旨在分析小型Hadoop集群中数据分层调度处理算法的原理、特点及其在计算机数据处理及存储服务中的应用。
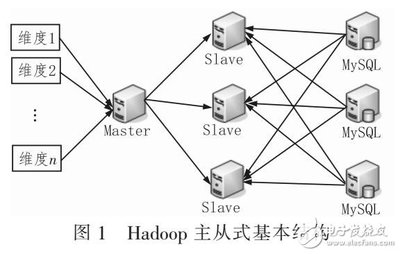
数据分层调度处理算法通过对数据按访问频率、重要性等维度进行分层,将热点数据与冷数据分别存储于不同层次的存储介质中,以实现资源的高效利用。在小型Hadoop集群中,由于计算和存储资源相对有限,分层调度算法通常结合Hadoop的HDFS和YARN组件,通过智能调度策略(如基于优先级的调度、动态资源分配)来平衡负载,避免资源瓶颈。
常见的数据分层调度算法包括基于时间局部性的LRU(最近最少使用)算法、基于访问频率的分层策略以及结合机器学习方法的自适应调度算法。在小型集群中,这些算法能够根据数据访问模式动态调整数据分布,例如将频繁访问的数据保留在高速存储层(如SSD),而将冷数据迁移至低成本存储层(如HDD)。这不仅提升了数据读取速度,还降低了存储成本。
在计算机数据处理及存储服务中,数据分层调度处理算法的应用显著提高了服务质量和系统可靠性。例如,在实时数据分析场景中,通过分层调度,小型Hadoop集群可以快速响应高优先级任务,减少延迟;在批处理任务中,算法通过合理分配资源,确保大规模数据处理的效率。同时,结合容错机制,这些算法还能在节点故障时自动调整数据分布,保障服务的连续性。
小型Hadoop集群在实施数据分层调度时也面临挑战,如算法复杂度带来的额外开销、分层策略的调优难度等。未来,随着边缘计算和云原生技术的发展,数据分层调度算法将更加智能化,例如引入强化学习进行动态优化,以进一步提升小型集群在数据处理及存储服务中的竞争力。
数据分层调度处理算法是小型Hadoop集群高效运行的关键,其在计算机数据处理及存储服务中的应用不仅优化了资源利用,还推动了大数据技术的普及与创新。未来的研究应聚焦于算法的轻量化与自适应能力,以应对日益复杂的数据处理需求。
如若转载,请注明出处:http://www.zhangyushuju.com/product/923.html
更新时间:2026-02-23 06:02:42